
Scott Chamberlin
4/15/2025
5 minutes
Agent Bedlam: A Future of Endless AI Energy Consumption?
We’re all infatuated with agents these days. Whether it’s the latest MCP-enabled platform, your vibe-coded instant success story, or maybe a ticking time bomb in disguise, agents are becoming the thing. Right now, their impact is small but growing rapidly. But let’s fast-forward to a future where these agents proliferate wildly, unchecked, triggering endless chains of other agents in some twisted pandemonium of computation. What happens then? Spoiler: chaos.
The Bedlam Analogy
Back in my Microsoft days, we had a phenomenon called email bedlam which occasionally brought down our entire internal Exchange servers. It goes something like this:
Someone emails a massive distribution list not typically used and inevitably, someone else replies with, "Please remove me." Then another person chimes in with the same request an so on. You've reached peak bedlam when you start getting the "Stop replying to all!"—to, you guessed it, the entire list. Rinse and repeat until every inbox is flooded, the email chain is now 10 pages long, and IT is breathing into paper bags. (Here’s the Wikipedia link for full context: Email Storm.) . That's what we called bedlam.
Now, imagine this—but with AI agents. What starts as a simple request to code the next unicorn app while you pop popcorn turns into a runaway feedback loop of agents triggering other agents, their network activity multiplying until systems buckle. And unlike email storms, this isn’t a once-in-a-blue-moon scenario. It could very well be the average case in a world with few constraints (either with basic web-requests or within a specific agent protocol like A2A). We are actually already seeing some early signs in the increased crawling costs due to AI and I imagine some of this is agent requests.
Modeling the Madness
This brings us to my latest fascination: modeling the energy impact of AI energy growth. Since my company, Neuralwatt, is focused on making AI energy-efficient, I started thinking about what unchecked agent bedlam could look like from an energy perspective. After all, while hardware and network limits will ultimately be the physical cap on the madness (likely only with great impact), I wanted to hone in on energy consumption to see at what point we get unchecked growth.
AI Energy Models—Monte Carlo to Find Bedlam
Many players in AI energy—Schneider, the IEA, etc.—have their AI energy models, full of projections for the not-so-distant future. But here at Neuralwatt (we punch above our weight), we decided to go a step further: let’s model the thresholds for agent bedlam.
Using a Monte Carlo simulation, I crafted a custom AI energy model grounded in the nitty-gritty of AI compute. My model factors in:
Tokens: Growth rates, probabilities of additional inference-time compute, recursive depth probabilities and most importantly the probability an agent will call another agent.
Hardware: Energy efficiency and performance gains (Nvidia GTC 2025 roadmap), hardware adoption rates, and eventual depreciation.
Let's start with a baseline simulation (thanks Schneider report which I referenced to tune my initial parameters) that shows solid, predictable growth. Here’s how it looks:

Then I cranked things up with a "More Growth" scenario (10% increase in key parameters from baseline). Probably getting out of the realm of manageability for existing infrastructure but within an order of magnitude of the baseline. Things are starting to heat up.
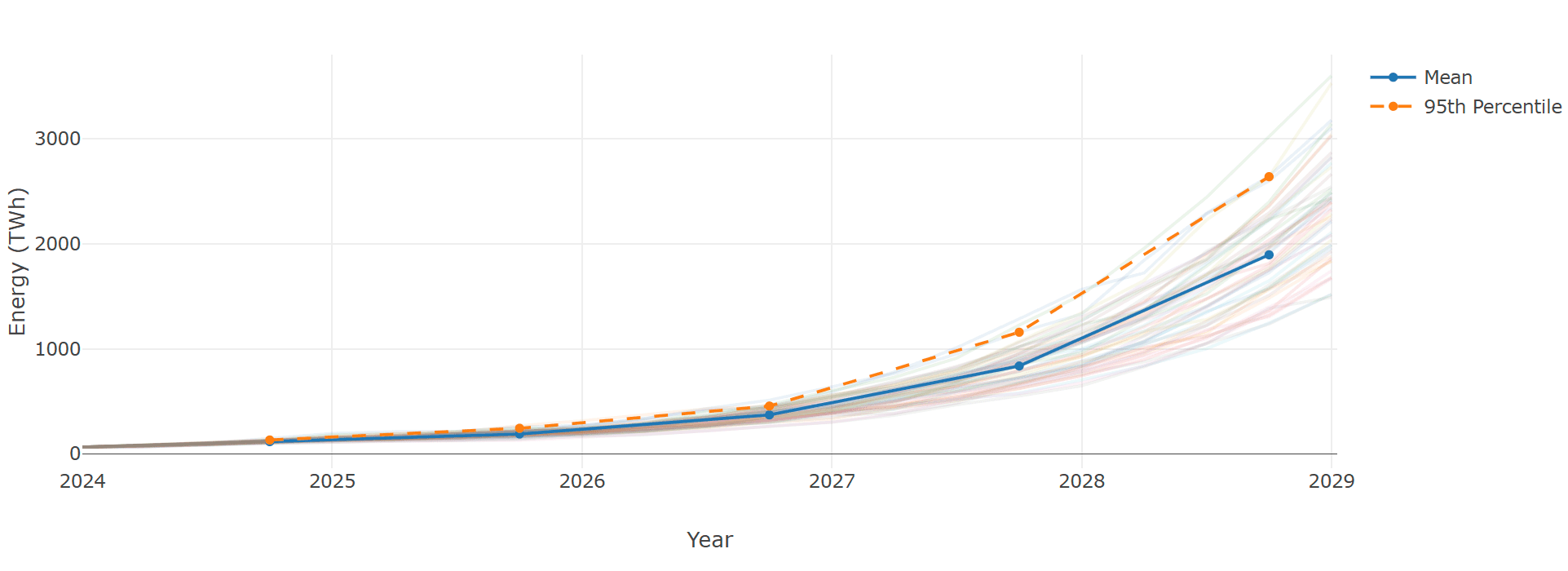
Finally, I unleashed the "Rapid Growth" model. Enter: chaos. This is where things break—geometric growth off the charts. And it didn't take too much in a mean increase in growth rate to this this.

Defining the Bedlam Threshold
I call it the Chamberlin Agent Bedlam Threshold :)—the growth rates where energy consumption shoots 100x above baseline, thanks to agent chaining probability growth. Here are two scenarios where we hit this milestone:
Agent Growth of 60% YoY, Trigger Probability of 10%, Max Recursion Depth of 7.
Agent Growth of 50% YoY, Trigger Probability of 60%, Max Recursion Depth of 19.
Boom. Energy bedlam achieved.
Is Bedlam Likely?
Probably not tomorrow, but is it worth paying attention to? Absolutely. Sustained 50%-60%+ growth rates over five years are unlikely to be purely hypothetical—we’re already seeing aggressive agent adoption in 2025 and I'm sure we are above that already in year 1 (large growth of small numbers).
Also just to be clear I'm not really saying that this 100x growth is even possible since you hit actual physical and compute constraints. What is more likely is that we are forced to grow these physical constraints faster than we've otherwise modeled or we get more congestion and less reliability due to unmanageable load.
Why is this different than what we've experienced in pre-AI agent days? First each basic request for an AI agent uses alot more energy than your basic web request. Second AI agents are generating orders of magnitude more requests per task than a human can while on a larger blast radius than a typical bad-acting piece of code. Third, this is the design of agents, it doesn't even require a bad actor to get us into this state it just requires a bit of growth on the autonomous requests + agent chaining at even a small level of probability.
Of course, we’d hit physical constraints (compute limits, power shortages) or maybe existing systems doing rate-limiting or service circuit-breakers would limit this well before hitting 100x energy growth. But what are those compute thresholds and can we model them with our model? That’s a topic for another post.
The Takeaway
At Neuralwatt, we’re hard at work refining our energy models—and this is just the beginning. Should you lose sleep over agent bedlam? Not today. But if AI’s energy impact has you tossing and turning, we’re here to help.
We’re planning to make our AI energy growth model available in the near future (maybe open-source, maybe as an app?). If you’re interested, reach out! And if OpenAI wants to share growth projections to make this even better, well, my inbox is open: scott@neuralwatt.com.
Let’s figure out how to grow responsibly—before we start seeing the negative impacts.
Appendix
Model parameters:
Simulation Parameters for Scenario: Baseline{ "simulation_config": { "monte_carlo_runs": 50, "periods_per_year": 4, "base_year": 2024, "simulation_years": 5, "max_recursion_depth": 10, "test_run": false, "debug_output": false, "base_datacenter_energy_twh": 65.0, "agent_trigger_probability": 0.15, "chain_energy_decay": 0.8, "reasoning_probability": 0.15, "token_growth_rate_mean": 1.0355580763416221, "token_growth_rate_std": 0.125, "task_complexity_growth_mean": 1.0241136890844451, "task_complexity_growth_std": 0.025, "agent_population_growth_mean": 1.0241136890844451, "agent_population_growth_std": 0.125, "inference_growth_rate_mean": 0.0625, "inference_growth_rate_std": 0.025, "inference_training_ratio": 0.6, "reasoning_growth_mean": 1.0355580763416221, "reasoning_growth_std": 0.025, "initial_agent_to_regular_ratio": 0.01 //Hardware population parameters "throughput_growth_rate": 3.3, // Updated based on Nvidia's Rubin roadmap (3.3x in one year) "efficiency_scaling_factor": 0.8, "min_utilization": 0.3, "max_utilization": 0.85, "power_cap_factor": 0.9, "depreciation_years": 5, // 5-year hardware lifecycle "latest_gen_utilization_mean": 0.70, // Initial deployment typically at 70% "latest_gen_utilization_std": 0.05, // Deployment variability "utilization_peak_year": 2, // Peak utilization typically in year 2-3 "peak_utilization_mean": 0.90, // Peak utilization around 90% "utilization_rampdown_curve": [1.0, 1.15, 1.20, 1.10, 0.95, 0.70], // Normalized utilization curve },
Simulation Parameters for Scenario: RapidGrowth{ "simulation_config": { "monte_carlo_runs": 50, "periods_per_year": 4, "base_year": 2024, "simulation_years": 5, "max_recursion_depth": 10, "test_run": false, "debug_output": false, "base_datacenter_energy_twh": 65.0, "agent_trigger_probability": 0.165, "chain_energy_decay": 0.8, "reasoning_probability": 0.15, "token_growth_rate_mean": 1.44978130687827094, "token_growth_rate_std": 0.125, "task_complexity_growth_mean": 1.33134779580977863, "task_complexity_growth_std": 0.025, "agent_population_growth_mean": 1.53617053362666765, "agent_population_growth_std": 0.125, "inference_growth_rate_mean": 0.0625, "inference_growth_rate_std": 0.025, "inference_training_inference": 0.6, "reasoning_growth_mean": 1.0355580763416221, "reasoning_growth_std": 0.025, "base_energy_growth_std": 0.025, "initial_agent_to_regular_ratio": 0.01 },//hardware parameters are the same
